
分析:亚马逊如何通过数据湖解决大数据挑战?
杰夫·贝佐斯(Jeff Bezos)往车库里下订单并亲自开车去邮局时,处理成本数字,跟踪库存和预测未来需求相对简单。快进25年了,亚马逊的零售业务在全球拥有175 多个配送中心,超过25万名全职员工每天运送数百万件商品。
亚马逊全球财务运营团队的任务非常艰巨,即跟踪所有数据(以PB为单位)。 在亚马逊的规模上,错误计算的指标(例如单位成本或数据延迟)可能会产生巨大影响(请考虑数百万美元)。团队一直在寻找更快地获取更准确数据的方法。
这就是为什么他们在2019年有一个主意:建立一个可以支撑地球上最大的物流网络之一的数据湖。后来它在内部被称为Galaxy数据湖。Galaxy数据湖建于2019年,现在所有各个团队都在努力将数据移入其中。
数据湖是一个集中式安全存储库,可让您以任何规模存储,管理,发现和共享所有结构化和非结构化数据。数据湖不需要预定义的架构,因此您可以处理原始数据,而不必知道将来可能要探索的洞察力。下图显示了数据湖的关键组件:
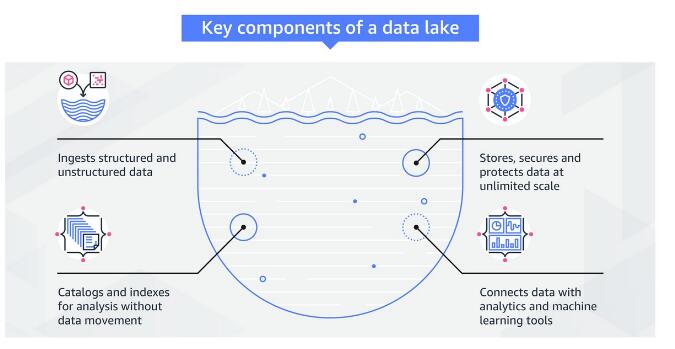
数据湖的关键组件
大数据的挑战
亚马逊面对大数据的挑战与许多其他公司面临的挑战相似:数据孤岛,分析各种数据集的难度,数据控制器能力,数据安全性以及整合机器学习。让我们仔细研究这些挑战,看看数据湖如何帮助解决它们。
打破数据孤岛
公司选择创建数据湖的主要原因是要打破数据孤岛。在不同地方拥有由不同组控制的数据包,本质上会掩盖数据。当公司快速发展和/或收购新业务时,通常会发生这种情况。就亚马逊而言,两者都是。
为了在国际上扩张并迅速创建新的运输计划(例如,免费当日交付或Amazon Fresh),大多数运营计划团队一直在控制自己的数据和技术。结果,数据以不同的方式存储在不同的位置。这种方法使每个团队都能解决问题,响应客户需求并更快地进行创新。
但是,很难在组织和公司范围内理解数据。它需要从许多不同来源手动收集数据。如此众多的团队独立运作,我们失去了可以通过共同解决问题而获得的效率。
从数据中获取详细细节也是困难的,因为不是每个人都可以访问各种数据存储库。对于较小的查询,您可以在电子表格中共享一部分数据。但是,当数据超出电子表格的容量时,挑战就出现了,这通常发生在大型公司中。在某些情况下,您可以共享较高级别的数据摘要,但实际上并没有获得完整的图像。
数据湖通过将所有数据合并到一个中央位置来解决此问题。团队可以继续充当敏捷单位,但是所有道路都通向数据湖进行分析。没有更多的筒仓。
分析各种数据集
使用不同的系统和方法进行数据管理的另一个挑战是数据结构和信息各不相同。例如,Amazon Prime拥有配送中心和包装商品的数据,而Amazon Fresh则有杂货店和食品的数据。
甚至国际运输计划也有所不同。例如,不同的国家有时会有不同的盒子尺寸和形状。来自“物联网”设备(例如,配送中心机器上的传感器)的非结构化数据也越来越多。
而且,不同的系统可能也具有相同类型的信息,但是其标签不同。 例如,在欧洲,使用的术语是“每单位成本”,而在北美,使用的术语是“每包装成本”。这两个术语的日期格式不同。在这种情况下,需要在两个标签之间建立链接,以便分析数据的人知道它指的是同一件事。
如果要在没有数据湖的传统数据仓库中合并所有这些数据,则需要大量数据准备以及导出,转换和加载或ETL操作。您将不得不权衡要保留的内容和丢失的内容,并不断更改刚性系统的结构。
数据湖可让您以任何格式导入任何数量的数据,因为没有预定义的架构。您甚至可以实时摄取数据。您可以从多个来源收集数据,并将其以原始格式移入数据湖。您还可以在信息之间建立链接,这些信息可能被标记为不同但代表同一件事。
将所有数据移至数据湖还可以改善传统数据仓库的功能。您可以灵活地将高度结构化,经常访问的数据存储在数据仓库中,同时还可以在数据湖存储中保留多达EB的结构化,半结构化和非结构化数据。
管理数据访问
由于数据存储在这么多位置,因此很难访问所有数据并链接到外部工具进行分析。亚马逊的运营财务数据分布在25多个数据库中,区域团队创建了自己的本地数据集版本。对于某些人来说,这意味着超过25个访问管理凭据。许多数据库都需要访问管理支持来执行诸如更改配置文件或重置密码之类的操作。此外,必须对每个数据库进行审核和控制,以确保没有人有不当访问权限。
借助数据湖,可以在合适的时间将合适的数据提供给合适的人变得更加容易。不必管理对存储数据的所有不同位置的访问,您只需要担心一组凭据。数据湖具有允许授权用户查看,访问,处理或修改特定资产的控件。数据湖有助于确保阻止未经授权的用户采取可能损害数据机密性和安全性的措施。
数据也以开放格式存储,这使得使用不同的分析服务更加容易。开放格式还使数据更有可能与尚不存在的工具兼容。您组织中的各种角色,例如数据科学家,数据工程师,应用程序开发人员和业务分析师,都可以使用他们选择的分析工具和框架来访问数据。
简而言之,您不必局限于一小组工具,而更多的人可以理解数据。
加速机器学习
数据湖是机器学习和人工智能的强大基础),因为它们在大型,多样化的数据集上蓬勃发展。机器学习使用从现有数据中学习的统计算法(称为训练的过程)来做出有关新数据的决策(称为推理的过程)。
在训练期间,将识别数据中的模式和关系以建立模型。该模型使您能够对从未遇到过的数据做出明智的决策。您拥有的数据越多,就越能训练您的机器学习模型,从而提高准确性。
亚马逊全球运营财务团队的最大职责之一是计划和预测亚马逊供应链的运营成本和资本支出,其中包括整个运输网络,数百个配送中心,分拣中心,配送站,全食超市,新鲜采摘场。上升点等等。
他们帮助回答重要的高级问题,例如“明年我们将运送多少包裹?” 和“我们将在薪金上花费多少?” 他们还解决非常具体的问题,例如“下个月我们在佛罗里达州坦帕市需要多少个不同大小的盒子?”

您的预测越准确,效果越好。如果您估计太低或太高,都可能产生负面影响,从而影响您的客户和利润。
例如,在亚马逊,如果我们预测需求太低,则配送中心的仓库工人可能没有足够的供应或驱动程序不足,这可能导致包裹延迟,更多的客户服务电话,订单被取消以及失去客户信任。如果我们预测过高,您可能会有库存和箱子围着仓库占用宝贵的空间。这种情况意味着对需求量更高的产品的空间较小。
像亚马逊这样的大多数组织都花费大量时间来预测未来。幸运的是,机器学习可以改善预测。去年,亚马逊运营财务团队进行了测试。他们采用了一部分预测,并将传统的手动流程与Amazon Forecast进行了比较。AmazonForecast是一项完全托管的服务,使用机器学习来提供高度准确的预测。在此试运行中,由Forecast所完成的预测平均比通过手动过程完成的预测准确67%。
通过将所有数据移至数据湖,亚马逊的运营财务团队可以结合数据集来训练和部署更准确的模型。使用更相关的数据来训练机器学习模型可以提高预测的准确性。此外,它还释放了手动执行此任务的员工来执行更具战略意义的项目,例如分析预测以推动现场运营的改善。
使用正确的工具:AWS上的Galaxy
亚马逊的零售业务使用某些技术,该技术早于2006年开始创建Amazon Web Services。在过去十年中,为了变得更具可扩展性,效率,性能和安全性,亚马逊零售业务中的许多工作负载已转移到AWS。Galaxy数据湖是内部称为Galaxy的大型大数据平台的重要组成部分。下图显示了Galaxy依赖AWS的某些方式以及它使用的某些AWS服务:
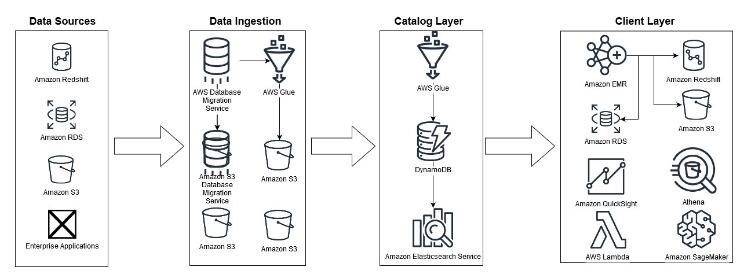
Galaxy数据湖基于Amazon的Simple Storage Service或对象存储服务S3构建。一些数据还存储在基于Amazon专有的基于文件的数据存储中,即Andes和Elastic Data eXchange,它们都是Amazon S3之上的服务层。其他一些数据源是数据仓库 Amazon Redshift ,Amazon Relational Database Service或RDS以及企业应用程序。
AWS Glue 是一项完全托管的ETL服务,可让您轻松准备和加载数据以进行分析,并且使用AWS Database Migration Service或DMS 将各种数据集加载到Amazon S3。Galaxy将来自多种服务(包括Amazon Redshift,Amazon RDS和AWS Glue数据目录)的元数据资产组合到基于Amazon DynamoDB(键值和文档数据库)构建的统一目录层中。Amazon Elasticsearch Service或 ES 用于在目录上启用更快的搜索查询。
在对数据进行分类或装入后,将在客户端层使用各种服务。例如,交互式查询服务Amazon Athena,用于使用标准SQL进行临时探索性查询;Amazon Redshift,一项用于更结构化的查询和报告的服务;和Amazon SageMaker,用于机器学习。
AWS湖形成
亚马逊团队从头开始创建了Galaxy数据湖架构。他们不得不在几个月内手动开发许多组件,这与其他公司过去必须这样做的方式类似。在2019年8月,AWS发布了一项名为AWS Lake Formation的新服务。
它使您可以简化数据湖的创建过程,并在几天(而不是几个月)内构建一个安全的数据湖。Lake Formation帮助您从数据库和对象存储中收集和分类数据,将数据移至新的Amazon S3数据湖中,使用机器学习算法对数据进行清理和分类,以及安全访问敏感数据。
摘要
通过以基于开放标准的数据格式将数据存储在统一的存储库中,数据湖可让您分解孤岛,使用各种分析服务从数据中获取最大的见解,并以经济高效的方式满足存储和数据处理需求随着时间的推移。
对于亚马逊的财务运营团队而言,Galaxy数据湖将为其全球用户提供集成体验。Galaxy的基础设施建于2019年,现在各种数据库系统都在迁移到数据湖中。使用该工具的团队现在已经看到了它的好处,理由是消除了手动流程和笨拙的电子表格,生产率的提高以及可用于增值分析的更多时间。

站内头条

NetApp 与 Google Cloud 合作,简化在云中扩展高性能工作负载的过程
2025-04-12
VergeIO推出 ioMetrics 监控平台,实现基础设施的深度可见性
2025-04-12
遵循 Zero Trust 的不可变备份存储是抵御勒索软件的最佳方法
2025-04-12
PNY 发布 PRO Elite 高耐用性 microSD 闪存卡,容量高达 512GB
2025-04-11
DDN 与 Google Cloud 合作,推进AI计划
2025-04-11
