
非结构化数据激增下的集群存储发展良机
一提到数据,不少人脑海里马上就会想到数据库,这个词能有如此高的知名度,完全得益于此前结构化数据在数据管理中的统治地位与人们对于其的重视。的确,在过去相当长的时期内,企业是数据制造的主体,而对于企业来讲,存在于数据库,应用于ERP、CRM等系统的结构化数据显然是最为重要的部分。而现在,随着信息制造主体的转变与信息化的普及,非结构化数据的管理日益成为业界热点,并且即使在企业内,非结构化数据的管理也逐渐成为了IT部门的重点课题。
激增的非结构化数据
据IDC的报告显示,现在全球数据量每18个月就要翻一番,每年全球产生的数据量已经高达40EB(1EB=1000PB)。而这些疯狂增长的数据主要来自非结构化数据。非结构化数据是相对于结构化数据而言,结构化数据主要是指那些数字的或能用统一的结构来表示的数据,如存储在数据库中的数据,这些数据基本上是以块(Block)的形式呈现。而非结构化数据是指那些无法用数字或统一的结构来表示的数据,像文本、图像、视频、音频、报表、网页等都是非结构化数据,它们大多以文件(File)的形式保存。
造成非结构化数据激增的原因主要有两个:一是云时代的到来使得数据创造的主体由企业逐渐转向用户个体,而个体所产生的绝大部分数据均为图片、文档、视频等非结构化数据;另一方面,信息化技术的普及使得企业更多的办公流程通过网络得以实现,以往纸质的表单、票据等现在都实现了数字化存档,而这方面产生的数据也以非结构化数据为主。
事实上,非结构化数据成为主流早有征兆,2008年,基于文件的存储系统容量出货量就以微弱的优势首次超过了基于块的存储系统容量的出货量,而近几年,这一差距正在逐渐拉大,据Gartner预计,到2012年,基于文件的存储系统容量将占到总容量的70%。而
IDC也同时预测,鉴于基于文件类型的非结构化数据的增速极快,到2012年,全球存储市场的总出货量中将有80%的容量被文件级数据所覆盖。
非结构化数据的特点
相比于业界一直重点关注的结构化数据,非结构化数据在生产、存储、使用上都有着不同的特点。
1、 生产速度快
一条结构化数据的大小往往是Byte级别,而非结构化数据的增长量级往往在MB级别,两者在生产速度上的差别显而易见,反映在存储容量上的区隔同样明显,一个结构化数据库的级别大都在GB级别,万一一个结构化数据库达到TB级别就算超大规模,而对于类似影视制作等以非结构化数据为主的企业来说,其所需要的存储空间往往有接近PB的规模。
非结构化数据这一特点反映在对于存储设备的的需求便是大的存储空间与方便灵活的扩展性能。
2、 文件级别的管理
与结构化数据使用的块级别存储不同的是,非结构化数据需要的是文件级别的存储技术。
在存储区域网络这种块级别存储架构中,主机直接通过SCSI或FC协议控制数据,而SAN存储设备无需完成文件的识别、管理等工作,这些工作都由主机来完成。
而面对非结构化数据,再采取这样的方式显然会加大主机的压力,因此非结构化数据需要文件级的存储设备,如何去处理这样的需求呢,按照传统的方式我们通常有两种方法,一方面,我们可以很容易的利用Windows或者Linux的文件服务器再加上直连存储系统或者SAN存储系统来构建出一台文件服务器来存放非结构化数据;另一种方法就是使用传统的NAS设备,NAS是一个拥有自己文件系统的存储设备,通过NFS或CIFS协议实现文件级的传输,但是,传统的NAS往往受到扩展性方面的限制,纵向(Scale-Up)扩展的方式很难适应当今非结构化数据激增的现实。




站内头条

NetApp 与 Google Cloud 合作,简化在云中扩展高性能工作负载的过程
2025-04-12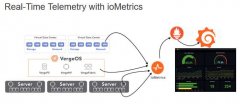
VergeIO推出 ioMetrics 监控平台,实现基础设施的深度可见性
2025-04-12
遵循 Zero Trust 的不可变备份存储是抵御勒索软件的最佳方法
2025-04-12
PNY 发布 PRO Elite 高耐用性 microSD 闪存卡,容量高达 512GB
2025-04-11
DDN 与 Google Cloud 合作,推进AI计划
2025-04-11
