
焱融科技拿下多项关键性能第一 剑指大模型训练优化
大模型存储新标杆,中国AI存储厂商焱融科技在多项性能指标上获世界第一。为大模型而生的存储长什么样?大模型爆发的三大堵点可归结为计算、存储、网络,其中存储在AI产业中的重要性不言而喻,它需要为海量多模态数据提供存储与高效管理,保障数据安全可靠,同时支持快速数据读取、并行计算、实时数据获取和缓存优化提升训练与推理效率。
在大模型产业飞速发展的同时,对存储的要求也水涨船高,存储系统在大模型时代正被改写。此前海外供应商占主导的全球存储市场也在被重塑,国内AI存储厂商在其中的地位愈发重要。
这也可以从一些权威组织的测评指标中看出来。去年,全球权威AI基准测评MLCommons组织首次推出了MLPerf存储基准测试(MLPerf Storage Benchmark),这也是目前首个唯一开源、公开透明的AI/ML基准测试。
上个月,该机构公布的MLPerf v1.0存储性能基准测试中,国内一家存储厂商崭露头角,其全闪存储产品在带宽、模拟GPU数量以及GPU利用率等关键性能指标上获得多项世界第一。

这就是成立于2016年的焱融科技,其最新推出的企业级全闪分布式存储一体机追光F9000X,实现了3节点存储集群的性能达到750万IOPS和270GBps带宽,可满足大规模训练、推理及高算力场景的需求。
焱融科技CTO张文涛谈道,大模型发展对存储系统在性能、稳定性和成本方面都提出了更高要求,这也正是其进行产品研发和优化的关键所在。

(图:焱融科技CTO张文涛)
就在9月底,全球权威AI基准测评厂商MLCommons公布的MLPerf v1.0存储性能基准测试结果中,焱融科技榜上有名。测试结果显示,其产品全闪F9000X在带宽、模拟GPU数量以及GPU利用率等关键性能指标上,拿下了多项世界第一。
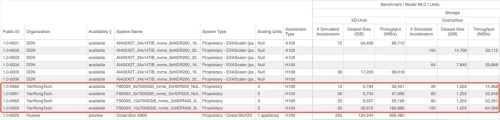
(图:MLPerf Storage测试结果公开数据)
在MLPerf Storage的测试中,包括3D-Unet、CosmoFlow和ResNet 50,焱融科技也是国内唯一一家参与了全部模型测试的存储厂商。
为了测试存储系统在支持机器学习工作负载方面的性能,测试规则中定义了存储系统可以采用单个计算节点运行多个ACC(Accelerators,加速器)进行相应模型应用测试,同时支持大规模分布式训练集群场景,多个客户端模拟真实数据并行的方式并发访问存储集群。
张文涛解释道,在大模型场景中,模型算力利用率(MFU)备受关注,在MLPerf对应的指标就是算力有效利用率(AU),MLPerf Storage要求AU达到90%,要求存储能使GPU利用率保持高位运行。在此之上,为了进一步体现存储支持模型训练的能力,存储系统需要尽可能提升其中单个计算节点中ACC的数量。
效率与成本,是大模型中的存储系统至关重要的两个点。这两点在MLPerf Storage的测试结果中都得到了验证。
测试结果显示,在分布式训练集群场景,焱融存储在所有三个模型的测试中,能够支撑的每个计算节点平均ACC数量和存储带宽性能均排名第一。
张文涛说,归根结底就是有效的算力利用率,只有存储足够快,在模型训练中,在存储中使用的时间越少,有效算力就越高。其次就是成本,单个存储节点提供的有效带宽越高,所需要的存储的集群规模越小,就意味着成本越低。
这项测试对于存储玩家的重要性不言而喻,既是存储系统的竞赛场,还是其客户选择合适产品的权威指南。
综合来看,整个大模型产业的急速发展,对存储系统提出了更高的要求,性能、稳定性和成本成为存储厂商必须越过的门槛。深谙技术创新与企业需求的焱融科技,在拿出更强计算能力、更高性能数据存储的方案后,为大模型时代的企业探索出了一条行之有效的路径。


站内头条
IDC:AI助力2024上半年中国公有云市场回暖
2024-11-28

致我超越,“1” 路同行,致态荣获京东SSD品类双料冠军
2024-11-12
GMIF2024 佰维存储“研发封测一体化2.0”:全链布局,助力客户价值跃升
2024-10-31
Supermicro推出完整的机架级液体冷却解决方案
2024-10-24
